I'm not really bullish on OpenAI. Why would they only compare with their own models? The only explanation could be that they aren't as competitive with other labs as they were before.
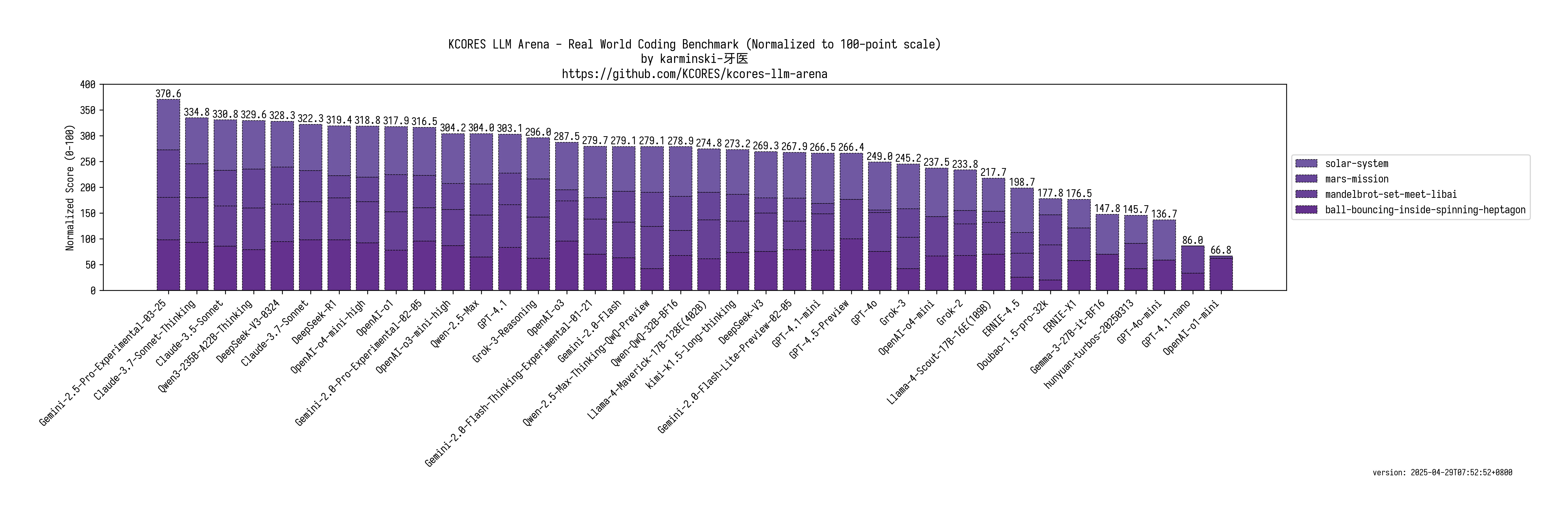
See figure 1 for up-to-date benchmarks https://github.com/KCORES/kcores-llm-arena
(Direct Link) https://raw.githubusercontent.com/KCORES/kcores-llm-arena/re...
I don't mind what they benchmark against as long as, when I use the model, it continues to give me better results than their competition.
Go look at their past blog posts. OpenAI only ever benchmarks against their own models.
Oh, ok. But it's still quite telling of their attitude as an organization.
It's the same organization that kept repeating that sharing weights of GPT would be "too dangerous for the world". Eventually DeepSeek thankfully did something like that, though they are supposed to be the evil guys.
{kind=link}